

The upcoming OpenSIPS 4.0 release already includes a new feature for the clusterer module dubbed “Cluster-Bridge Replication”. It mainly targets setups with multiple, geo-distributed data centers which make use of WAN links to exchange clustering data. Re-organizing the nodes into islands connected by bridges allows considerable bandwidth savings, especially if the WAN links are over public internet. At the time of writing, the only module benefiting from cluster-bridge replication is ratelimit, with its pipes replication.
To fully understand this feature, let’s start by revisiting the default cluster replication mechanism in OpenSIPS:
Full-Mesh Replication
This is the standard way of replicating data in an OpenSIPS cluster. We have N OpenSIPS nodes, so there will be N * (N-1) cluster data links between them. A full-mesh replication topology, where every node replicates data to every other node.
While it seems like a lot of redundancy is going on, in practice you actually want every one of these replication channels, so the data propagates to the remote nodes as soon as possible. Example features enabled by full-mesh replication:
- distributed concurrent-call counters, at platform-level, not just server-level (using the dialog module)
- distributed calls-per-second counters (using the ratelimit module)
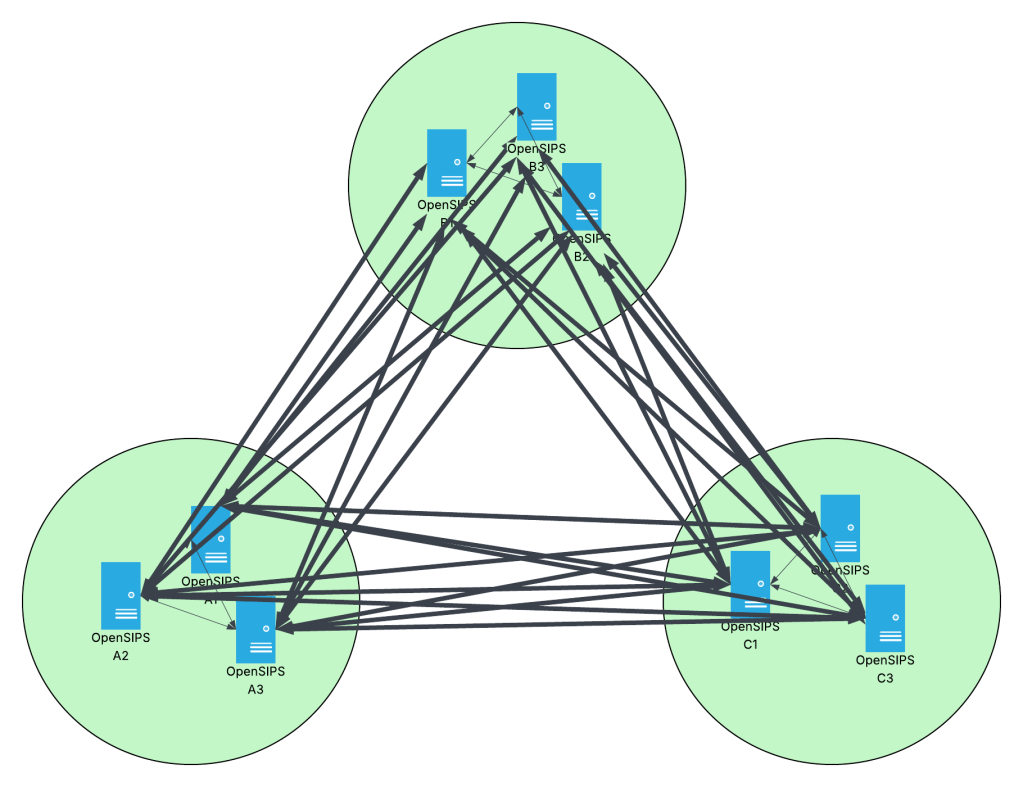
The main advantage of full-mesh replication is its simplicity: it is intuitive and straight-forward to set up. However, the disadvantage is equally big: it quickly runs into scalability issues. In the above diagram, we can see that on a platform with just a handful of nodes, there are already 27 WAN links, or inter-data center links. Typically, WAN links tend to be slower and may run into throughput limitations, especially if the replication frequency is high (e.g., see ratelimit’s repl_timer_interval setting, with a default interval of 200 ms!). Now, for each data center, imagine there are 18 outgoing clusterer module links trying to push CPS counters over the internet to the other data centers, every 200 ms. You can already see how the WAN link quickly becomes a bottleneck…
So let’s get back to the drawing board. With full-mesh replication, assuming we have N data centers, each having M OpenSIPS instances, the number of full-mesh links is: M2 * N * (N-1) / 2.
Can we do better and optimize the topology such that we free up the WAN links while still correctly replicating data to all OpenSIPS instances?
Cluster-Bridge Replication
Enter what we have called: “cluster-bridge replication”. By default, different OpenSIPS clusters were not made to replicate data to each other. If you wanted the same data replicating to all nodes, they would need all to be in the same cluster. So we had to make a few extensions to the clusterer module (backwards-compatible, no worries), so we can achieve something like this:

As you can see, we now have three different clusters, each corresponding to a data center. Then, we build a full-mesh replication topology between the datacenters themselves, rather than individual nodes. Each DC links to each other DC using a single clusterer link (TCP connection). To define these cross-cluster replication links, we have introduced a new SQL table, called clusterer_bridge:
mysql> select * from clusterer_bridge;
+----+-----------+-----------+------------+-------------------------------+
| id | cluster_a | cluster_b | send_shtag | dst_node_csv |
+----+-----------+-----------+------------+-------------------------------+
| 1 | 1 | 2 | wan1 | bin:10.0.0.212,bin:10.0.0.213 |
| 2 | 1 | 3 | wan3 | bin:10.0.0.214,bin:10.0.0.215 |
| 3 | 2 | 1 | wan1 | bin:10.0.0.210,bin:10.0.0.211 |
| 4 | 2 | 3 | wan2 | bin:10.0.0.214,bin:10.0.0.215 |
| 5 | 3 | 1 | wan3 | bin:10.0.0.210,bin:10.0.0.211 |
| 6 | 3 | 2 | wan2 | bin:10.0.0.212,bin:10.0.0.213 |
+----+-----------+-----------+------------+-------------------------------+
6 rows in set (0,00 sec)
The clusterer_bridge definitions allow full control over the sender and receiver nodes, so you can spread the workload among all OpenSIPS instances. For example, DC-A may replicate data to DC-B using OpenSIPS node O1, but replicates data to DC-C using OpenSIPS node O2.
There is high-availability included on both sender and receiver ends, as follows:
- sender side: the sender is decided by a sharing tag. Whichever node owns this sharing tag will be responsible for the periodic data broadcasts.
- receiver side: the receiver is given by a failover list of nodes, to be always tried in the same succession. If the send fails to 1st node, try 2nd node, 3rd node, etc. until the send succeeds.
Extra logic is expected in any modules which implement cluster-bridge replication in order to propagate the data received over bridge links within the local cluster.
Finally, in terms of complexity, we assume the same N data centers each having M OpenSIPS instances. The number of inter-DC links with bridge replication is now only: N * (N-1) / 2, as we have fully eliminated the M term! Substituting for N=3 data centers, we have 3 * 2 / 2 = 3 inter-DC links. The math checks out! 🧑🎓
Usage & Documentation
The new feature is already fully available on OpenSIPS master branch. Documentation can be found in both clusterer and ratelimit modules. To begin using it with ratelimit, all you need is to enable the bridge_replication module parameter, after defining the clusters and bridges in their respective SQL tables, of course.
But how useful is this feature for you? Does it spark any extra data replication channels you can now build into your VoIP platform? Alternatively, can you suggest ways to improve it?
