
 OpenSIPS 2.4 is all about clustering and SIP presence is an important service that delivers a large variety of functionalities like end-to-end user presence, BLF, SLA and more. We need to consider clustering for presence as much as presence is a service with a large appetite for storage and processing – presence is mainly about aggregating and distributing large XML based documents. Shortly, presence must be clustered in order to scale and be redundant.
OpenSIPS 2.4 is all about clustering and SIP presence is an important service that delivers a large variety of functionalities like end-to-end user presence, BLF, SLA and more. We need to consider clustering for presence as much as presence is a service with a large appetite for storage and processing – presence is mainly about aggregating and distributing large XML based documents. Shortly, presence must be clustered in order to scale and be redundant.
Prior to OpenSIPS 2.4, the presence support had a basic ability of sharing – of sharing presence data (subscribers/watchers and presentities) between multiple running OpenSIPS servers. This is achieved by forcing the presence engine to cache nothing and to use all the time an SQL database for storing the data – this is activated by enabling the module parameter “fallback2db”.
Still, this ability to fully share the data via SQL DB is not sufficient for scaling, nor for failover. The missing link is a mechanism to coordinate and share the actions over the data between the servers. It is not enough to share the presentity data if the servers are not able to coordinate and to decide which server will fire the notifications to watchers when the presentity is detected as expired. While using the older version, the actions (like expiring of watchers or presentities) will be internally triggered by all instances, leading to duplicated notifications to users and to multiple conflicting DB operations.
Having the above as a starting point, let’s see what OpenSIPS 2.4 brings in terms of clustering for the presence services. The easiest way to explain is by visiting the most used clustering scenarios, like High-Availability, Load Balancing, Federating data, and more.
High-Availability scenario
In order to implement a hot stand-by, you need to fully share the data between the active and backup server and to coordinate them in terms of taking actions over the data. The data sharing mechanism is already there for a while; but the coordination of the actions is something newly introduced in OpenSIPS 2.4 .
In order to coordinate one or more server (in terms of taking actions), the “ownership” concept was introduced. Basically, in order to take actions over an subscription (like expiring it and sending notifications), a server must own that subscription. Of course, only one server may own the subscription. The ownership mechanism is implemented via “tags” – a subscription has only one tag attached to it. In the same time a server may be aware of one or more tags – some tags in active state, some in inactive state. The servers will take actions only on the subscriptions marked with a tag which is active on that server. By making active a tag on a different server, we can pass the responsibility of handling a set of subscription between the servers.
Now, let’s see how we use the tagging in order to implement an active-backup setup. In such cases, usually the servers sit behind a Virtual IP (VIP) controlled by High-Availabilities tool like VRRPD, Heartbeat and others. The VIP directs the traffic only to one servers. The other one (typically the backup) does not receive any traffic. As we want the backup to be completely idle, we want it to take no actions too – so, we need to correlate the tag with the HA status. Shortly, the tag will be active on the active server from VIP perspective.
Let’s use the tag named “VIP”, which by default will be active on the active server. So all the actions will be taken by this server. A mandatory part of such setup is a shared SQL DB between the two servers – again, this is used for fully sharing the data between the servers. Due the shared database, both servers will be aware of the same data set, but only the active server will receive the traffic (due the VIP address) and will take the actions (due the active tag).
When the HA tool switches the VIP between the servers, you will need to activate the tag (by using an MI command) on the newly active server, so will take full task in handling the presence service.
Here is a snippet of the relevant configuration parameter for the presence module:
modparam("presence", "fallback2db", 1) # full DB sharing
modparam("presence", "cluster_id", 1)
modparam("presence", "cluster_sharing_tags", "vip=active")
Load Balancing scenario
In such scenario we have multiple active servers. Each server receives part of the presence traffic – there are no constraints in how the traffic is split between the servers. In order to provide a unitary service, all servers must fully share the presence data via a shared SQL DB. Each server will be responsible of the subscription it receives (in terms of taking the actions). If a server goes down, its duties will be transfered to another server – of course, there is a need of an external tool to monitor the servers and to detects the failures.
Here, the tags map on the servers – each server will have a tag. In normal operations the tag will be active on the corresponding server (and all the tags of the other servers will be inactive). This means each server takes care of its own subscriber set (as received via SIP traffic).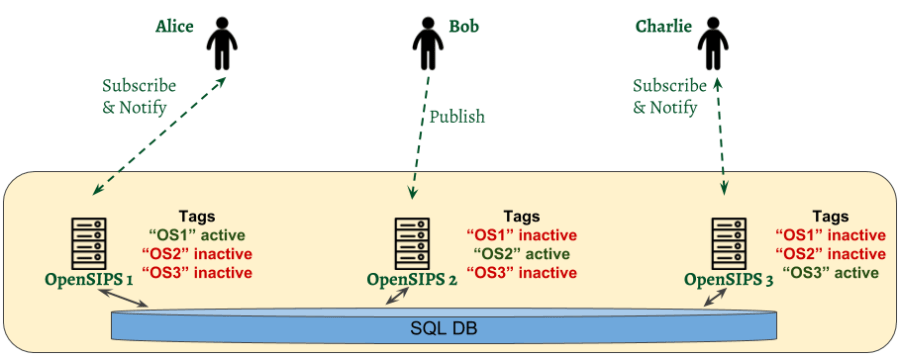
When a server is detected a failed, its tag will be made active (via an MI command) on any of the remaining servers. This operation will delegate a new server to take care of the subscribers which were handled so far by the failed server. Here is an example of how to move the “OS2” tag from OpenSIPS 2 to OpenSIPS 3 if OpenSIPS 2 fails, by running this MI command on OpenSIPS 3:
opensipsctl fifo pres_set_sharing_tag_active OS2
At any moment, you can double check what are the active tag on a server by running
opensipsctl fifo pres_list_sharing_tags
Federating scenario
All the above scenarios were based on full data sharing between all the servers – each server has access to the entire data set of subscribers and presentities. But this may become a bottleneck when you have a geo-distributed system or when you have a large set of data.
In such cases, you should consider the federating scenario where the data is partitioned across the servers and all the servers work together through the clustering mechanism to offer an unitary presence server via all the servers/nodes.
In the federated scenario, each server holds only the data it needs – it will store only the local subscribers (received via SIP) and the local presentitie (received via SIP). Still, the nodes do share via clustering layer their presentities either via broadcasting (when a new Publish is received on a node), either via querying (when a node is querying the rest of the cluster for a presentity). 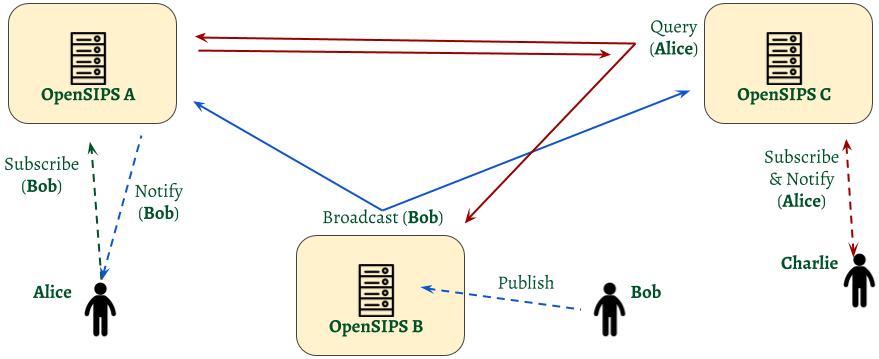
As you noticed, there is no shared DB involved in this scenario. The possible interactions between the nodes at the clustering level are:
- presentity broadcast – when a node receives a Publish via SIP, it will locally store it and then broadcast the extracted presentity in the cluster. On the receiving nodes side, only the nodes interested in that presentity (as having subscribers to that presentity) will process the broadcast presentity; if the node has no subscribers for that presentity, it will simply ignore the broadcast.
- presentity query – when a node receives a local Subscribe via SIP, it will also broadcast in the cluster a query on that presentity – maybe the presentity is already known on a different node. Only the nodes having the presentity received via SIP will answer back to the querying node. To optimize the traffic in the cluster, each node will remember the presentities it queried for, so it will not query again for the same presentity.
In the federating scenario, the nodes are keeping their own data set and they share pieces of data only on demand (and strictly what is needed) – this reduces the clustering traffic.
Here is a snippet of a node configuration in a federating cluster:
modparam("presence", "fallback2db", 0) # no DB sharing
modparam("presence", "cluster_id", 1)
modparam("presence", "cluster_federation_mode", 1)
modparam("presence", "cluster_pres_events" ,"presence , dialog;sla")
Note that in this scenario, there is no data redundancy (and no failover). If a node goes down, all its data (local subscribers and local presentities) will be lost. Nevertheless, the remaining cluster will continue to function with the remaining data.
Federating scenario with redundancy
In order to address the data redundancy issue of the federating scenario, we can image a mixed scenario, a combination between the typical HA and federating scenarios. In each location, there are two servers (instead of one), using a local database to share the date and a local tag to coordinate the actions between the two of them.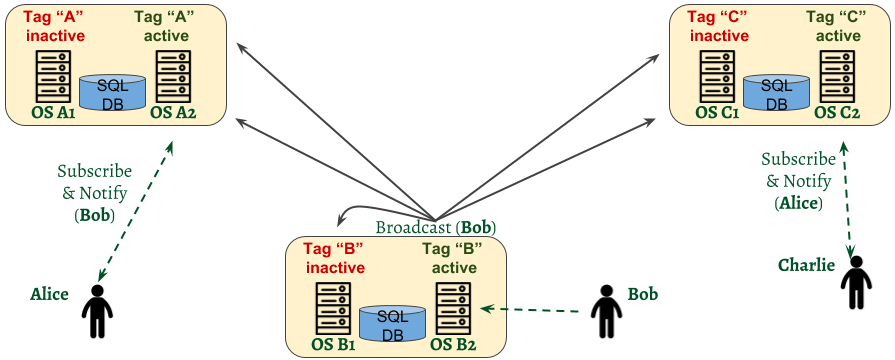
Considering the above setup, all the six servers are part of the federating cluster. In each location, the 2 servers can be configured into a HA setup or in a Load Balancing setup, using local DB and locally used tag. Note that being part of the same cluster, the tags will be “visible” on all the nodes – still, as usage, they have a local scope (at each location level).
Here is a snippet of a node configuration in location A:
modparam("presence", "fallback2db", 1) # do DB sharing
modparam("presence", "cluster_id", 1)
modparam("presence", "cluster_sharing_tags", "A=backup")
modparam("presence", "cluster_federation_mode", 1)
modparam("presence", "cluster_pres_events" ,"presence , dialog;sla")
Conclusions
The new clustering engine in OpenSIPS 2.4 made possible the addition of clustering support for presence. Even more, it made it possible in multiple ways (data sharing versus federating), allowing the creation of complex clustering scenarios.
Need more practical examples ? Join us to the OpenSIPS Summit 2018 in Amsterdam and see the Interactive Demos about the presence clustering support in OpenSIPS 2.4 .
